-- 发布时间:2/27/2010 5:06:00 PM
-- 计算机光盘软件与应用2010年1期-基于单向指针链表的快速搜索算法的实现
《计算机光盘软件与应用》杂志征稿函
《计算机光盘软件与应用》杂志是由中国科学院主管、大恒电子出版社主办的国内外公开发行的综合性国家级学术期刊。本刊致力于创办以创新、准确、实用为特色,突出综述性、科学性、实用性,及时报道国内外计算机技术在科研、教学、应用方面的研究成果和发展动态,为国内计算机同行提供学术交流的平台。
联系人:刘编辑
电 话: 010-67626884
邮 箱:jsjzzs@gmail.com
文/李静
一、前言
在TC或VC程序设计过程中,某些情况下需要经常性地对一组数据进行比较搜索。比如在一些实时监测的安全系统中,为了及时对系统进行监测,就需要对系统内的每一个新线程或进程进行快速检测,而且这个工作可能是经常性的,检测的同时会利用一些黑白名单和被检测的目标进行比对,以确定目标是否合法,以便做出迅速反应。这样在系统设计时应该尽可能考虑到做到反应速度快,占用资源少的特点。所以在制定设计方案时,常常为了节省内存,加快程序的运行速度,数据读入内存后经常采用单向指针链表的方式存放,但是传统方式下基于链表方式的数据比较采用的是逐点顺序比较的方式,如果以后数据越来越大,查询的时间过程会越来越长,严重影响系统性能。为了避免在数据查询方面占用的大量时间,有必要研究出一种基于单向指针链表的快速查询算法,来提高查询的速度,但是目前在这方面并没有发现具体算法或实现代码的相关资料,因此我们自行设计出基于单向指针链表形式数据的快速搜索算法,同时结出了具体的实现代码。
二、单向指针链表查询算法的实现原理
在VC程序中没有提供现成的函数来对单向指针链表进行查询,由于单向指针链表的数据存储方式采用的是首尾相连的方式,每一个节点只保留了本节点的数据、上一节点的地址、下一节点的地址三部分内容,因此给单向指针链表的查询带来一定困难,为了提高查询速度我们结合目前已经比较成熟一些算法原理设计了一套用于单向指针链表的二分搜索的查询算法,可大大提高链表的查询速度。在这个算法中,我们必须先生成满足搜索条件的几个基本数据:一是先有序排列链表,二是统计链表节点数。基本思想分为两步:一、有序地从小到大重排单向指针链表并统计链表节点数,二、设计一个节点位置指针,采用二分法搜索单向指针链表。
三、算法设计
算法中关键是如何在单向指针链表中实现二分法搜索,下面为我们设计的链表搜索的算法过程:
(一)搜索过程
假设:节点已经按从小到大排列
Num:为链表节点总数。
Head:为单向指针链表头节点。
Sp:为搜索区的起始位置指针。
Cp:为当前位置指针。
Dp:为目标节点位置(此处假设位于总链表的11/16位置处)。
P0:为搜索区的单向指针链表开始位置号。
P1:为搜索区的单向指针链表结尾位置号。
则搜索过程如图1所示:
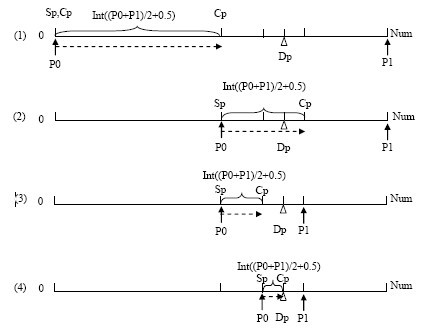
图1 基于链表指针的二分搜索查询算法过程
说明:
搜索(1):Sp,Cp先指向头节点,P0为搜索区起始节点位置,P1为搜索区终节点位置,搜索从Sp开始向后移int((P0+P1)/2+0.5)个节点,把Cp指向这个节点。0.5的意义是P0+P1为偶数时移动(P0+P1)/2个节点,为奇数时移动(P0+P1+1)/2个节点。再比较*Cp与目标*Dp的值,这时*Cp<*Dp,进行下一个搜索。
搜索(2):Sp改指向Cp节点位置,P0值改为int((P0+P1)/2+0.5)为新搜索区起始节点位置,P1为搜索区终节点位置,搜索从Sp开始向后移int((P0+P1)/2+0.5)个节点,把Cp指向这个节点,再比较*Cp与目标*Dp的值,这时*Cp>*Dp,进行下一个搜索。
搜索(3):P0为搜索区起始节点位置,P1值改为int((P0+P1)/2+0.5)为新搜索区终节点位置,搜索从Sp开始向后移int((P0+P1)/2+0.5)个节点,把Cp指向这个节点,再比较*Cp与目标*Dp的值,这时*Cp<*Dp,进行下一个搜索。
搜索(4):Sp改指向Cp节点位置,P0值改为int((P0+P1)/2+0.5)为新搜索区起始节点位置,P1为搜索区终节点位置,搜索从Sp开始向后移int((P0+P1)/2+0.5)个节点,把Cp指向这个节点,再比较*Cp与目标*Dp的值,这时*Cp=*Dp,搜索完成。
(二)代码实现
BOOL Find_data(char file[100],int link_long, struct Link_stru, struct *Link_stru_head)
{
if(data_long!=0 && strlen(file)>0)
{
float p=0,p0=1,p1=float(Link_long);//存储开始和结尾点数字
struct Link_data *cp,*sp;
cp=sp= Link_stru_head;
//检查第一位是否为匹配数据
if(cp->Link_data==file)
return 1;
do{
if(p0<int((p1+p0)/2+0.5))
{
for(p=p0;p<int((p1+p0)/2+0.5);p++)//移动指针
cp=cp->next;
if(cp->Link_data==file)//当前数据为匹配数据
return 1;
else
{
if(cp-> Link_data <file)//搜到数据比程序数据小,当前指针改为当前那个
{
sp=cp;//cp不变,作为起搜节点
p0=int((p1+p0)/2+0.5);
}
else//搜到数据比程序数据大,当前指针改为原来那个
{
cp=sp;
p1=int((p1+p0)/2+0.5);
}
}
}
}while(p1!=p0 && p!=int((p1+p0)/2+0.5) );
return -1;//没找到
}
else
return -1;
}
其中:
File:要查询的数据。
Link_long:链表长度。
Link_stru:链表结构,存放了单向指针链表数据,结构中的元素Link_data存放了数据内容。并且该单向指针链表已从小到大排好序。
四、总结
在所有的编语言中,VC和TC的指针概念是其独有的,也是较难理解的一部分,指针的提出给C语言的编程带来了极大的灵活性,同时也提高了编程的难度和出错的概率,一个小错误很可能就会造成系统的崩溃。在单向指针链表方面也是一样,数据的处理难度相对较高,需要更加细心的考虑算法过程和细节。本文就单向指针链表的搜索方面进行了一些探索,并给出了一个可用的快速搜索算法的具体实现过程和实现代码。在实际的使用过程中此算法被证明在数据较多时可极大地提高搜索速度。
 此主题相关图片如下:
此主题相关图片如下: